Sentinel’s watchlist is a collection of entities that can be used to correlate your logs with a rarely changing data set. Although watchlists can be updated via the Azure Portal GUI or even its API, watchlists are typically left in Sentinel unmaintained and untouched for extended periods.

I commonly encounter some watchlists in a client’s SIEM when reviewing existing Sentinel instances. Even though some of them are tiny —just a few MB— I occasionally encounter watchlists that are more than 100 MB. I frequently find watchlists that were created in the past but are no longer used by the customer.
The problem is that watchlists generate recurrent expenses on your Sentinel, which many users are unaware of. As a result, they just leave the older, unneeded elements in their Sentinel until they hit the technical limits of the watchlists.
I have also observed companies using watchlists as a cost-saving measure. They were unaware that the use of a watchlist would ultimately result in higher expenses than utilizing a standard table because of the behavior of watchlists. This is because the recurring cost of a watchlist was not previously stated on the official watchlist page.
Cost of a Watchlist
In Sentinel you pay a set amount of money for each gigabyte that you send there. Watchlists are not exempt from this cost element.
A watchlist and a regular table differ primarily in that a watchlist generates extra logs over time and during particular activities. When you upload a watchlist, its content is transmitted into the ‘Watchlist’ Sentinel table (initial ingestion), for which you must pay. After this, watchlist data is repeatedly pushed to Sentinel in order to maintain its availability for rules. This refresh process takes place once every twelve days.
Furthermore, each time you add, edit, or remove a watchlist item, a new event is added to the “Watchlist” table. If you understand how the ‘_GetWatchlist’ function works, this is not even shocking, yet many people are still unaware of it. Now let’s examine the built-in _GetWatchlist function:
union Watchlist, ConfidentialWatchlist
| where TimeGenerated < now()
| where _DTItemType == 'watchlist-item'
| where WatchlistAlias == watchlistAlias
| summarize hint.shufflekey=_DTItemId arg_max(_DTTimestamp, _DTItemStatus, LastUpdatedTimeUTC, SearchKey, WatchlistItem) by _DTItemId
| where _DTItemStatus != 'Delete'
| project-away _DTTimestamp, _DTItemStatus
| evaluate bag_unpack(WatchlistItem) It is clear that the summarize line only displays the most recent entry for each item based on its _DTTimestamp value and then the ‘where’ condition after it just removes all deleted entries. To make this work, each delete operation must insert a new record into the ‘Watchlist’ table with the ‘_DTItemStatus’ set to ‘Delete’. Thus, when a watchlist item is deleted, a new event in the ‘Watchlist’ table will be created.
Also, every time a value is changed, a new event is created. Thus, by displaying only the most recent event generated for a watchlist entry, one will only see the item’s current value. This is handled by the ‘summarize’ part of the code again.
Automatic refresh
As per the MS documentation, each (non-deleted) entry in a watchlist is ‘refreshed’ once every 12 days. An Analytics rule can only look back 14 days. Microsoft probably pushes it more often to make sure you have all the data needed for your rules at your disposal.
My tests showed that logs are being initially refreshed at intervals ranging from 11 days 7 hours to 11 days 23 hours. So, in actuality, it occurs more frequently than once every 12 days. Following the first setup of the watchlist, every automatic push (refresh) occurred between 1 AM and 2:30 AM UTC. It’s possible that these fixed refresh times are why the initial refresh took less than 12 days.
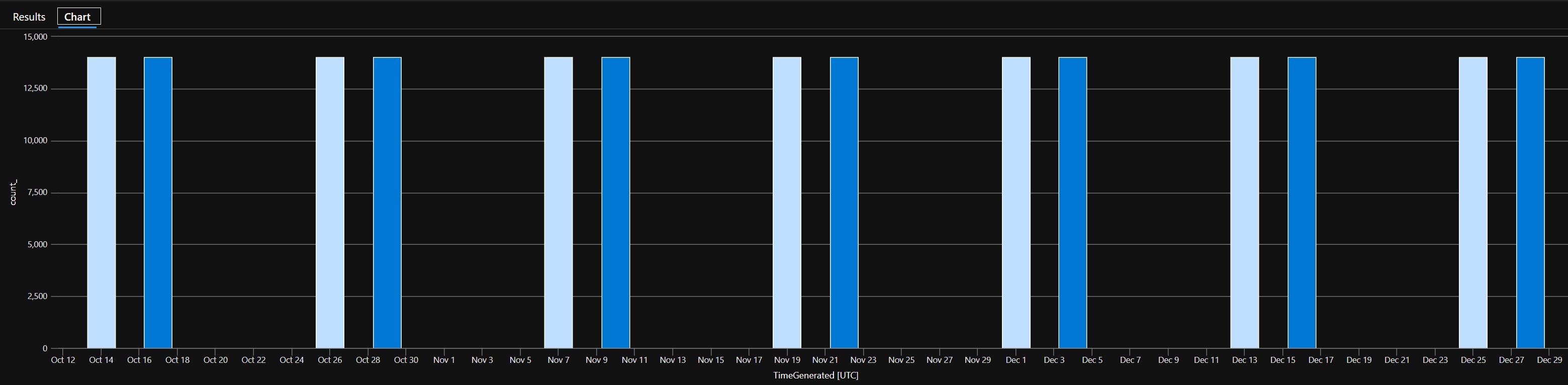
Various watchlists are represented by different colors in the graphic. The repeated ingestion, which occurs roughly every 12 days, is shown in the illustration. As can be seen, the initial watchlist was made on October 14 and the first refresh took place on October 26. On October 17th, the second watchlist was created, and on October 29th, it was re-ingested.
This functions similarly to the ThreatIntelligenceIndicators table.
I began writing this article a long time ago, but before I publish it, I always open a ticket with Microsoft and ask them to validate specific details to ensure everything in my post is correct. Even though my ticket has not yet been resolved, Microsoft has updated their official article about watchlists in the meanwhile. The 12 day refresh period is now reflected on that page, however this information was not previously out.
The price and simplicity of use of various lookup options
You have five different alternatives to consider when implementing a lookup table:
1. Watchlist
In Sentinel, you can utilize a standard watchlist, or if you require a larger data collection, you can keep your watchlist in blob storage. The latter allows the use of watchlists up to 500 MB in capacity, but otherwise they work identically.
-
Cost: (what kinds of expenses the solution incurs and how often)
Every 12 days, data is pushed into the Watchlist table. As a result, even if the data is not modified, it generates a recurring fee every 12 days.
Any changes or deletions of a watchlist entry will create a new event for that entry in the ‘Watchlist’ table.
As a result, you must pay at least twice for each entry - once for creation and once for deletion. If you utilize the data for longer than 12 days, you must also pay to have it refreshed. And you must pay for the re-ingestion of a single entry every time it is updated.
-
Availability: (the ease with which analytics rules can use the data)
The _GetWatchlist() function is a special method that always displays the data in your watchlist, regardless of the underlying event’s TimeGenerated attribute. If you utilize this function, regardless of whether your time filter is set to the last 5 minutes or the last 7 days, you will always see the watchlist items.
All of the items in your watchlist, regardless of when they were pushed to your Sentinel, are still accessible even if your rules are set up to check the latest 2 hours of data (just an example). So, regardless of the lookup period, you will be able to see all of the watchlist entries using the _GetWatchlist() function. Thus, you don’t have to recreate all of your rules to cover a bigger time window.
If you want to look up more than 2 days of data, your query frequency must be more than or equal to 1 hour, according to an analytics rule requirement. As a result, you cannot write a rule that checks 14 days of data every 15 minutes. However, because the watchlist data is constantly available, you can easily construct rules that run every 15 minutes and do not miss any entries from a watchlist.
This availability feature is a really big benefit of the watchlists.
-
Maintenance: (How simple it is to delete irrelevant info while still keeping the necessary data usable?)
You must remove any watchlists or items from watchlists that you no longer want to use; otherwise, they will be pushed to your Sentinel repeatedly. As a result, in the case of a watchlist, you must deal with the cleanup of older items yourself.
However, because the data is automatically refreshed, you don’t have to manually recreate entries that you want to utilize over a longer period of time.
Its API and Logic Apps actions make it convenient to manage. It is very simple to configure it on the GUI as well, which is why it is the most popular way for whitelisting specific actions and assets in Sentinel.
2. Threat Intelligence dataset
Sentinel’s Threat Intelligence capability can be used to store simple entities such as URLs or IP addresses.
-
Cost:
It functions similarly to a watchlist. It inserts the data into the ThreatIntelligenceIndicators table in your Sentinel. When you add, alter, or delete a new indicator, a new event is created. Furthermore, the data is renewed every 12 days.
While watchlists can contain a variety of values, the TI function can only contain simple information like as IP addresses or URLs. Every event also has a lot of metadata like expiration, confidence score, etc. So, if your list is simple, the TI function will be more expensive due to the added metadata overhead.
-
Availability:
The data can only be viewed if the time window is configured to cover it. This means that if a TI entry was created in the ThreatIntelligenceIndicators table two days ago, your query and rule must be modified to look back at least two days.
Because the events are refreshed every 12 days, you must technically adjust all of your TI-based rules to look back 14 days *(just to be sure). This is also how all of the built-in Microsoft rule templates that use the ThreatIntelligenceIndicators database function. As a result, you must adjust all of the Analytics rules to cover 14 days.
As a result, if you want to use the TI function reliably, the linked rules must have a frequency greater than 1 hour. At least 1 hour is needed to be able to look back 14 days (Analytics rule limitation). This problem is not there in case of watchlists.
-
Maintenance:
TI entries can have their expiration dates configured. When an entry expires, a new ‘deleted’ event is added to the table. As a result, you are not required to maintain the TI table yourself. TI providers often configure this value, but if you feed data into this feature yourself, you can automatically apply an expiration date to each entry.
Because of automatic refresh, the data you intend to utilize for a longer period of time and have set to expire later will be available to you. You are not required to manually re-ingest the logs.
3. Pushing data into a normal table
Instead of using a dedicated feature, you can also store your data in Sentinel using a regular custom table.
-
Availability:
Analytics rules can only access data if the logs were created within the time frames specified by your rules. So, if your events were pushed two days ago and your rule is set to scan the previous 24 hours, your events will be inaccessible to the rule (unlike a Watchlist).
You can forward the logs into a table every day to avoid the query frequency issue, however the cost will be higher. You can also push it less regularly, such as every 12 days, but you will have to look up the last 12 (14) days with your rules, which will require your rules to be adjusted and you will be unable to perform the queries at a lower frequency.
-
Cost:
You pay for ingestion when you push the data into the table.
Removal occurs automatically during the phase-out of a log (after retention and archiving). This means that, in contrast to a watchlist, you are not charged for deletion.
To meet all of the requirements, you should probably push the logs at least once every 12 days so that your rules may use the data. If you need to push the data more regularly, the cost will rise because you will have to re-ingest the data several times. So, if you want to execute a rule every 15 minutes, you can only look back 2 days (Analytics rule limitation), which means you must re-ingest the data at least every 2 days. This will considerably raise the price.
-
Maintenance:
You will not have to deal with the removal of events because they will be phased out over time (after the chosen retention and archiving period), but you will have to deal with the re-addition of events you wish to utilize them for a longer duration. This is due to the fact that events are not accessible by Analytics rules after 14 days.
4. Using the externaldata operator
Instead of storing data in Sentinel, you can use the externaldata operator to read information from another external source.
-
Cost:
As there is no ingestion taking place, it is free to use in Sentinel.
You must keep this information somewhere, which may incur external fees. You will pay Storage account-related fees if you store the data set in a Storage account, for example.
-
Maintenance:
Because the logs are not in Sentinel, you do not need to re-ingest or delete them. However, you must still control the file at its source.
You can use third-party files, such as those from a GitHub repository. In this scenario, management will be handled by someone else rather than you. If you have faith in this third party, it can relieve you of all management responsibilities.
Because the files are stored outside of Sentinel, managing them can be difficult if you plan to do it yourself. However, it is dependent on the solutions you have in place to manage these files.
-
Availability:
Because these logs were not technically ingested into your Sentinel, they lack a ‘TimeGenerated’ attribute. Thus, they are available at all times, regardless of the set lookup period.
-
Misc:
You must host your data and make it available to Sentinel. This typically involves making the data public or establishing access keys.
Because the events are not kept in the Sentinel, auditing can be difficult. As a result, if the file is changed, it can be difficult to determine why a rule triggered or did not trigger. This is especially problematic if you use a lookup file hosted by an unknown third party, such as a GitHub repository owned by someone other than yourself.
5. Sentinel function
You can create a Sentinel function to store unstructured data. A function can store complex KQL queries or really simple list of values. It is similar to adding a ‘lookup’ table to all of your queries one-by-one, but it is more manageable.
-
Cost:
It costs nothing to create or use a Sentinel function.
-
Availability:
There are no time constraints. Data kept in a Sentinel function is accessible at all times. As a result, you do not need to modify or re-design your rules in order to use them, and they can run at any frequency.
-
Maintenance:
Deploying and removing functions are straightforward, but because the data is unstructured, altering current data might be more difficult. There is no natural mechanism to determine whether a particular IP is represented as an element of a list in a Sentinel function.
So, removing certain pieces (rather than the entire function) or adding a new element can be difficult, and you will need to write your own code/function to manage this.
In comparison to the other alternatives, configuring it on the GUI for whitelisting purposes can be inconvenient.
Comparison
Comparsing some possible scenarios.
| Scenario | Cost | Rule modification | Keeping the required logs | Removing unwanted logs | Manageability |
|---|---|---|---|---|---|
| Watchlist | Medium | Not needed | Automatic | Need to be handled | Easy on the GUI / Good API |
| Normal table with no re-ingestion | Medium / Low | Needed (logs can be old, so the query need to be reworked) | - (not applicable in this scenario) | Automatic | Good API |
| Normal table with daily re-ingestion | High | Potentially Not needed (we re-ingest the logs, so logs will be available) | Daily re-ingest based on usage needs to be solved | Automatic | Good API |
| TI database | Medium | Needed (rules have to look back 14 days and they cannot use low frequency) | Automatic | Automatic (if expiration is configured) | Easy on the GUI / API not recommended |
| Externaldata managed by you | Free | Not needed | Automatic | Need to be handled outside of Sentinel | Solution dependent, not trivial |
FAQ
Because there are so many possible ways of implementing a lookup table, each with their own set of advantages and disadvantages, I frequently get questions during deployment. Some examples:
-
Which choice is the most affordable?
Using the externaldata operator or a Sentinel function can be the cheapest option because you can implement these solutions for free. These may be the best choice in terms of price, but they have certain technological drawbacks.
-
Which solution is the easiest / simplest to manage?
In this scenario, it is critical to understand who wants to manage it and what the use case is. SOC wishes to administer a lookup table in order to whitelist specific machines. In this scenario, the simplest method is a watchlist, which SOC analysts may quickly modify on the GUI.
You want to make sure that no outdated data is being refreshed. Pushing data to a custom table is a fantastic solution if it meets your objectives because it will roll out outdated data over time. You can also set an expiration date with the TI functionality. Ultimately, the best option will be determined by your use case.
Using the API to manage data? The API documentation for a watchlist is the most comprehensive, with numerous examples, so it may be a suitable option. Using the API, you can also easily push data to a table. In my experience, the TI API documentation is inadequate, thus I cannot suggest it at this time.
-
TI vs Watchlist?
This is entirely dependent on the application.
It is a good rule of thumb to use TI if you intend to leverage third-party TI feeds, your own custom-managed dataset with basic values (only list of IPs, URLs, etc), and/or Microsoft’s built-in rules based on the TI table.
Watchlists are the way to go if your data set is more complicated (not a list of single entities), you need more flexibility or an easy way to handle it, or you want less constraints with rule generation.
-
When to push the data into a custom table?
At first glance, the custom table solution could seem like the worst choice that ought to be avoided. This is because it has the majority of the shortcomings of the alternative options.
In actuality, though, it might be beneficial in a few particular situations. For instance, let’s say you want to send a data set for a single use to your Sentinel. For example, you may have a list of IP addresses that you only intended to correlate with your logs today. However, you may wish to do the same thing with a different fresh batch of data tomorrow and discard the previous values.
When it comes to a watchlist, you have to pay for the costs of both ingestion and deletion. Therefore, you will still be required to pay twice if you wish to utilize a watchlist item and then drop it. However, with a custom table, you just need to pay for data ingestion; after that, the data is automatically rolled out free of charge. A custom table can therefore be 50% less expensive than a watchlist if you have a rapidly changing data collection that you only plan to utilize for a very short amount of time.
Some fun last section here
When dealing with a lookup table, the conventional practice is to use the watchlist options. However, because of its restrictions and cost, sometimes choosing an alternative is a no-brainer. Thus, knowing all of the ins and outs of these possibilities, as well as having all of the information regarding one’s use cases, is quite vital here. There is no single best choice for every case.
When choosing your lookup solution, keep the following considerations in mind at all times:
- Who will handle the data management and what qualifications do they have?
- What kind of information do you wish to keep?
- How sensitive is the information?
- What is the intended use of the data — will it be included in rules?
- How long do you plan to retain and use the information?
- How often will you update, delete, or add new data?
- How important the cost is over other factors?
- How big your data set is?